- Summing Amplifier Definition: A summing amplifier is an op amp configuration that outputs a weighted sum of multiple input signals.
- Op Amp Basics: Op amps are used in various configurations, with the summing amplifier being one popular application.
- Circuit Configuration: The summing amplifier uses an inverting amplifier setup, where multiple inputs are paralleled at the inverting input.
- Functionality and Theory: By grounding the non-inverting input and applying Kirchhoff’s Current Law, the output is derived from the sum of scaled input voltages.
- Practical Application: An example of a summing amplifier with three inputs demonstrates how to calculate its output voltage, providing a hands-on understanding of the concept.
An operational amplifier, or op amp, is not only an amplifier; it can also perform a summing operation. This allows us to design a circuit that combines several input signals into a single output, creating a weighted sum of these inputs.
The summing Amplifier is one variation of inverting amplifier. In inverting amplifier there is only one voltage signal applied to the inverting input as shown below,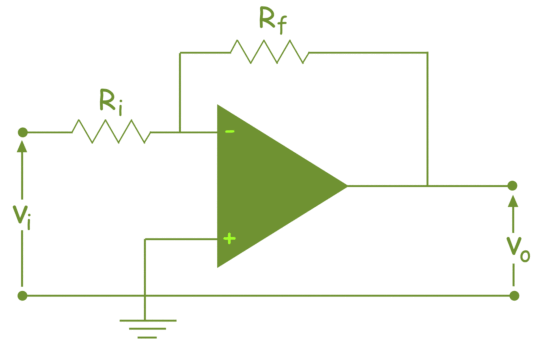
A basic inverting amplifier can be transformed into a summing amplifier by connecting several input terminals in parallel to the existing input.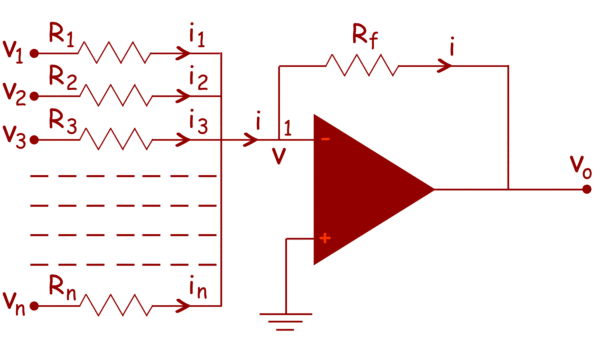
In this configuration, multiple input terminals are connected in parallel. The non-inverting terminal of the op amp is grounded, setting its potential to zero, and assuming an ideal op amp, the inverting terminal’s potential is also zero. So, the electric potential at node 1, is also zero. From the circuit, it is also clear that the current i is the sum of currents of input terminals.
Therefore,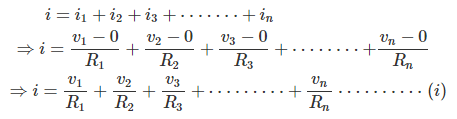
Now, in the case of ideal op amp the current at the inverting and non-inverting terminal are zero. So, as per Kirchhoff Current Law, the entire input current passes through the feedback path of resistance Rf. That means,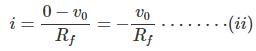
From, equation (i) and (ii), we get,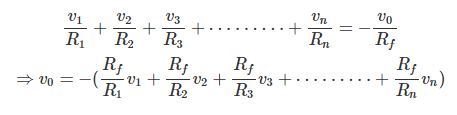
This indicates that output voltage v0 is weighted sum of numbers of input voltages.
Example of summing Amplifier
Let us calculate the output voltage of 3 inputs summer or summing amplifier, circuit as shown below,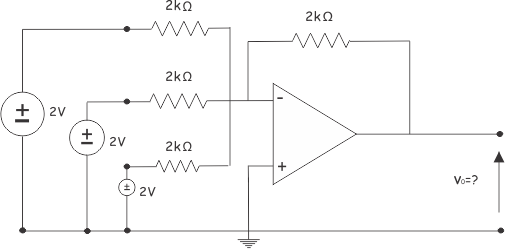
Here, as per equation of summing amplifier,